Datakalab, the new AI-related startup that Apple has bought
According to the latest information, Apple would be working on iOS and iPadOS to bring its first major language model (LLM)…

According to the latest information, Apple would be working on iOS and iPadOS to bring its first major language model (LLM)…

Rumors around iOS 18 are growing very quickly and focus, above all, on the growing interest of...

Today we test much more than a CarPlay adapter, because this Ottocast P3 AI is a mini computer for...

A week after the second Beta of iOS 17.5, the third Beta arrives along with the corresponding iPadOS,…

On our Mac we can know how much space we are using in different file categories and how much space is available in…

Apple has announced its next presentation event for the next iPad and it will take place on May 7...

The design of the iPhone 16 remains a mystery although the hardware and battery capacities vary...

The passing of the days brings us closer to WWDC24, one of Apple's most important events in the...
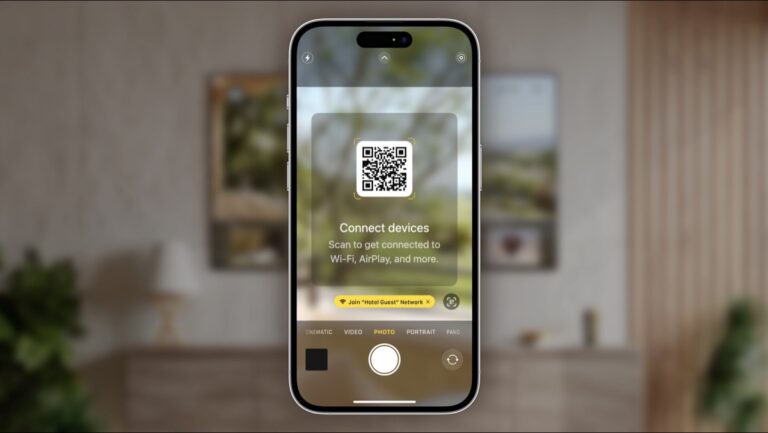
iOS 17 was presented in June last year at WWDC23 and almost a year later there are some features...

iPhone is always at the forefront of being able to prioritize fixes in its features. And it is not far behind, since…

We already have the first alternative application store to the App Store, the AltStore, which at the moment only has...