為了與競爭對手競爭,蘋果已經開始將更多的賭注押在人工智能上。 Google或Facebook毫無疑問地收集用戶數據並認識到他們這樣做是為了改善人工智能和機器學習(Machine Learning)系統,但是Apple並不這麼認為。 Cupertinos確實關心我們的隱私。 因此,在上一屆WWDC中,他們告訴了我們有關 差異隱私,您的系統可以收集數據,改善您的AI並同時保護我們的隱私。
其他公司一直想知道我們在哪裡,買什麼或如何使用鍵盤等信息,其中包括我們想要的東西,但似乎這從未使蘋果擔心過,蘋果公司從理論上講,這與您的客戶數據無關:他們不銷售廣告,僅銷售其產品。 蒂姆·庫克和公司 提供安全的設備 這樣用戶也可以放心,這是Apple不想更改的事情。
差異隱私研究一般,保護個人
作為一些專家 機器學習 而對於AI而言,蘋果的問題在於,如果它不做任何事情,那麼在虛擬助手方面將比競爭對手落後光年。 這就是我們過去被告知的差異性隱私發揮作用的地方。 WWDC。 克雷格·費德里希(Craig Federighi)這樣解釋:
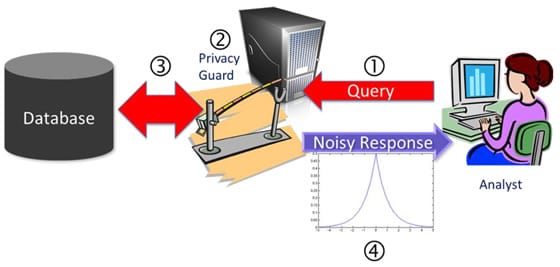
差異隱私是統計和數據分析領域的研究主題,它使用哈希算法,子採樣和噪聲注入來允許從許多來源進行此類學習,同時保持每個用戶的信息完全私有。
差異隱私 不是蘋果的發明。 學者們對該概念進行了多年研究,但是隨著iOS 10的發布,Apple將開始使用此概念來收集和分析來自鍵盤,Spotlight和Notes用戶的數據。
差分隱私由 單個數據的算法編碼,因此一旦分析了成千上萬個用戶的數據以收集大規模趨勢模式,就無法控制該人。 目的是在獲得有助於改善機器學習的一般信息的同時,保護用戶的身份及其數據的詳細信息
iOS的10 在將數據批量發送到Apple之前,它將在設備中隨機地隨機播放我們的數據,因此永遠不會以不安全的方式發送數據。 另一方面,Apple不會存儲我們用鍵盤輸入的每個單詞或執行的搜索,因為如上所述,因為它不需要它。 庫比蒂諾人說,他們將限制他們可以從每個用戶那裡收集的數據量。
蘋果向教授提供了實施差異隱私的文件 亞倫·羅斯(Aaron Roth) 這位來自賓夕法尼亞大學的教授,可以說是《差異性隱私(差異性隱私的算法基礎)》的作者,並且將蘋果在這一領域的工作描述為“開創性”或“開創性的”。
差異隱私的工作原理

差異隱私並不是一項獨特的技術。 這是一種數據處理方法, 創建限制以防止數據與用戶相關 具體的。 它允許對數據進行整體分析,但會給數據增加一些噪音,這意味著在批量處理數據的同時不會損害個人隱私。 亞當·斯密(Adam Smith)對其定義如下:
從技術上講,這是一個數學定義。 它只是限制了數據處理的不同方式。 而且它以不允許鏈接太多有關該數據組中任何單個區間提取點的信息的方式限制了它們。
另一方面,他將差異性隱私與能夠從調諧不良的收音機中找出靜噪層背後的潛在旋律進行了比較:
一旦您了解了所聽到的內容,就很容易忽略靜電。 因此,這有點像每個人都會發生的事情,您不會從一個人身上學到太多,但是總的來說,您可以清楚地看到各種模式。
史密斯認為 蘋果是第一家嘗試使用差異隱私的主要公司 大範圍上。 AT&T之類的其他公司也進行了研究,但還不敢使用它。
人工智能的未來?
人們通常通過執法來審視矽谷的隱私辯論,該辯論權衡了隱私和國家安全。 對於公司而言, 爭論在於隱私與功能之間。 蘋果公司已經開始採取的行動可能會從根本上改變這場辯論。
谷歌和Facebook,以及其他公司,試圖解決如何提供具有許多功能且同時保持私有性的優質產品的問題。 默認情況下,Google的最新消息傳遞應用程序Allo和Facebook Messenger都不提供端到端加密,因為兩家公司都需要用戶數據來改善其機器學習並使其機器人發揮作用。 蘋果還希望收集用戶數據,但不會刪除 iMessage端到端加密。 史密斯說,蘋果的實施可能會導致其他公司改變主意。
簡而言之,似乎蘋果公司敢於使用已經存在的理論來在不侵犯我們隱私的情況下從許多人那裡收集數據的系統。 有人會復制你嗎?